|
transformer理论部分见机器学习笔记:Transformer_刘文巾的博客-CSDN博客
1 导入库
import math
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
2 数据集处理
S: decoder输入的起始符号 E: decoder输出的终止符号 P: 出现不等长的sequence的时候,用来补长
# S: Symbol that shows starting of decoding input
# E: Symbol that shows endng of decoding output
# P: Symbol that will fill in blank sequence
# if current batch data size is short than time steps
sentences = [
# enc_input dec_input dec_output
['ich mochte ein bier', 'S i want a beer .', 'i want a beer . E'],
['ich mochte ein cola', 'S i want a coke .', 'i want a coke . E']
]
#encoder input和decoder input就不用说了,分别是transformer中encoder和decoder的输入
#decoder output就是我们理论上需要输出的东西(ground truth)(预测的句子和这个进行比对,算loss)
#这里的输入数据集只是两对英德句子,每个字的索引(vocab)也是手动编码上去的
src_vocab = {'P' : 0, 'ich' : 1, 'mochte' : 2, 'ein' : 3, 'bier' : 4, 'cola' : 5}
# Padding Should be Zero
#每一个batch里面的句子长度是一样的,那么不足的部分就需要补Padding
src_vocab_size = len(src_vocab)
tgt_vocab = {'P' : 0, 'i' : 1, 'want' : 2, 'a' : 3, 'beer' : 4, 'coke' : 5, 'S' : 6, 'E' : 7, '.' : 8}
idx2word = {i: w for i, w in enumerate(tgt_vocab)}
#idx2word 键值是数字,value是对应的英文单词
tgt_vocab_size = len(tgt_vocab)
src_len = 5
# enc_input max sequence length
#encoder 输入的句子的长度(不足的部分补padding)
tgt_len = 6
# dec_input(=dec_output) max sequence length
#decoder输出的目标句子的长度(算上起始符S和终止符E之后)
3 transformer的参数
# Transformer Parameters
d_model = 512
#每一个词的 word embedding 用多少维表示
#(包括positional encoding应该用多少维表示,因为这两个要维度相加,应该是一样的维度)
d_ff = 2048
# FeedForward dimension
#forward线性层变成多少维
#(d_model->d_ff->d_model)
d_k = d_v = 64 # dimension of K(=Q), V
#K,Q,V矩阵的维度
#K和Q一定是一样的,因为要K乘Q的转置
#V不一定,这里我们认为是一样的
'''
换一种说法,就是我在进行self-attention的时候,
从input(加了位置编码之后的input)线性变换之后的三个向量 K,Q,V的维度
'''
n_layers = 6
#encoder和decoder各有多少层
n_heads = 8
#multi-head attention有几个头
4 数据预处理
将encoder_input、decoder_input和decoder_output进行id化
def make_data(sentences):
enc_inputs, dec_inputs, dec_outputs = [], [], []
for i in range(len(sentences)):
#对于输入的每一句话
enc_input = [src_vocab[n] for n in sentences[i][0].split()]
# 每一次生成这一行sentence中encoder_input对应的id编码
for _ in range(src_len-len(enc_input)):
enc_input.append(0)
#encoder_input 补长
dec_input = [tgt_vocab[n] for n in sentences[i][1].split()]
# 每一次生成这一行sentence中decoder_input对应的id编码
for _ in range(tgt_len-len(dec_input)):
dec_input.append(0)
#decoder_input补长
dec_output = [tgt_vocab[n] for n in sentences[i][2].split()]
# 每一次生成这一行sentence中decoder_output对应的id编码
for _ in range(tgt_len-len(dec_output)):
dec_output.append(0)
#decoder_output补长
#分别对encoder-input、decoder-input、decoder-output进行处理,分别放到一个list里面
enc_inputs.extend(enc_input)
dec_inputs.extend(dec_input)
dec_outputs.extend(dec_output)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
#一定要是LongTensor
enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
print(enc_inputs,'\n', dec_inputs,'\n', dec_outputs)
'''
tensor([[1, 2, 3, 4, 0],
[1, 2, 3, 5, 0]])
tensor([[6, 1, 2, 3, 4, 8],
[6, 1, 2, 3, 5, 8]])
tensor([[1, 2, 3, 4, 8, 7],
[1, 2, 3, 5, 8, 7]])
'''
5 构建dataloader
要使用pytorch的dataloader,有以下两种构造方法 第一种方法——构造MyDataSet类,我们需要自己实现__len__方法和__getitem__方法 第二种方法 使用TensorDateset
具体可见 pytorch笔记:Dataloader_刘文巾的博客-CSDN博客
5.1 MyDataSet
class MyDataSet(Data.Dataset):
def __init__(self, enc_inputs, dec_inputs, dec_outputs):
super(MyDataSet, self).__init__()
self.enc_inputs = enc_inputs
self.dec_inputs = dec_inputs
self.dec_outputs = dec_outputs
def __len__(self):
return self.enc_inputs.shape[0]
#有几个sentence
def __getitem__(self, idx):
return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
#根据索引找encoder_input,decoder_input,decoder_output
loader = Data.DataLoader(
MyDataSet(enc_inputs, dec_inputs, dec_outputs),
batch_size=2,
shuffle=True)
for step,(b_e_i,b_d_i,b_d_o) in enumerate(loader):
print(b_e_i,'\n',b_d_i,'\n',b_d_o)
'''
tensor([[1, 2, 3, 4, 0],
[1, 2, 3, 5, 0]])
tensor([[6, 1, 2, 3, 4, 8],
[6, 1, 2, 3, 5, 8]])
tensor([[1, 2, 3, 4, 8, 7],
[1, 2, 3, 5, 8, 7]])
'''
5.2 TensorDataset
torch_dataset=Data.TensorDataset(enc_inputs, dec_inputs, dec_outputs)
loader2=Data.DataLoader(
dataset=torch_dataset,
batch_size=2,
shuffle=True)
for step,(b_e_i,b_d_i,b_d_o) in enumerate(loader2):
print(b_e_i,'\n',b_d_i,'\n',b_d_o)
'''
tensor([[1, 2, 3, 5, 0],
[1, 2, 3, 4, 0]])
tensor([[6, 1, 2, 3, 5, 8],
[6, 1, 2, 3, 4, 8]])
tensor([[1, 2, 3, 5, 8, 7],
[1, 2, 3, 4, 8, 7]])
'''
6 Transformer结构 (总体)
我改变一下顺序,先看一下总体的Transformer框架
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder().cuda()
self.decoder = Decoder().cuda()
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False).cuda()
#对decoder的输出转换维度,
#从隐藏层维数->输出词典大小(选取概率最大的那一个,作为我们的预测结果)
def forward(self, enc_inputs, dec_inputs):
'''
enc_inputs维度:[batch_size, src_len]
对encoder-input,我一个batch中有batch_size个sequence,一个sequence有src_len个字
dec_inputs: [batch_size, tgt_len]
对decoder-input,我一个batch中有batch_size个sequence,一个sequence有tgt_len个字
'''
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
# enc_outputs: [batch_size, src_len, d_model],
# d_model是每一个字的word embedding长度
"""
enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]
注意力矩阵,对encoder和decoder,每一层,每一句话,每一个头,每两个字之间都有一个权重系数,
这些权重系数组成了注意力矩阵
之后的dec_self_attns同理,当然decoder还有一个decoder-encoder的注意力矩阵
"""
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
# dec_outpus: [batch_size, tgt_len, d_model],
#dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len],
#dec_enc_attn: [n_layers, batch_size, tgt_len, src_len]
dec_logits = self.projection(dec_outputs)
#将输出的维度,从 [batch_size, tgt_len, d_model]变成[batch_size, tgt_len, tgt_vocab_size]
# dec_logits: [batch_size, tgt_len, tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
'''
dec_logits view了之后的维度是 [batch_size * tgt_len, tgt_vocab_size],可以理解为,
一个长句子,这个句子有 batch_size*tgt_len 个单词.
每个单词用 tgt_vocab_size 维表示,表示这个单词为目标语言各个单词的概率,取概率最大者为这个单词的翻译
'''
#Transformer 主要就是调用 Encoder 和 Decoder。最后返回
7 Encoder 结构
7.1 Encoder结构整体
nn.Embedding原理可见 pytorch 笔记: torch.nn.Embedding_刘文巾的博客-CSDN博客
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model)
#对encoder的输入的每个单词进行词向量计算(src_vocab_size个词,每个词d_model的维度)
self.pos_emb = PositionalEncoding(d_model)
#计算位置向量
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
#将6个EncoderLayer组成一个module
def forward(self, enc_inputs):
'''
enc_inputs: [batch_size, src_len]
'''
enc_outputs = self.src_emb(enc_inputs)
#对每个单词进行词向量计算
#enc_outputs [batch_size, src_len, d_model]
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1)
#添加位置编码
# enc_outputs [batch_size, src_len, d_model]
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs)
# enc_self_attn: [batch_size, src_len, src_len]
#计算得到encoder-attention的pad martix
enc_self_attns = []
#创建一个列表,保存接下来要返回的字-字attention的值,不参与任何计算,供可视化用
for layer in self.layers:
# enc_outputs: [batch_size, src_len, d_model]
# enc_self_attn: [batch_size, n_heads, src_len, src_len]
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
#再传进来就不用positional decoding
#记录下每一次的attention
return enc_outputs, enc_self_attns
#使用 nn.ModuleList() 里面的参数是列表,列表里面存了 n_layers 个 Encoder Layer
#由于我们控制好了 Encoder Layer 的输入和输出维度相同,所以可以直接用个 for 循环以嵌套的方式,
#将上一次 Encoder Layer 的输出作为下一次 Encoder Layer 的输入
7.2 positional encoding
buffer和parameter部分可见pytorch笔记 pytorch模型中的parameter与buffer_刘文巾的博客-CSDN博客
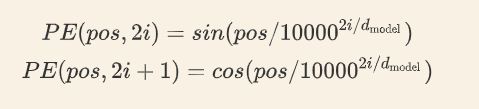
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
#max_len (一个sequence的最大长度)
pe = torch.zeros(max_len, d_model)
#pe [max_len,d_model]
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
#position [max_len,1]
div_term = torch.exp(
torch.arange(0, d_model, 2).float()
* (-math.log(10000.0) / d_model))
div_term:[d_model/2]
#e^(-i*log10000/d_model)=10000^(-i/d_model)
#d_model为embedding_dimension
#两个相乘的维度为[max_len,d_model/2]
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
#计算position encoding
#pe的维度为[max_len,d_model],每一行的奇数偶数分别取sin和cos(position * div_term)里面的值
pe = pe.unsqueeze(0).transpose(0, 1)
#维度变成(max_len,1,d_model),
#所以直接用pe=pe.unsqueeze(1)也可以
self.register_buffer('pe', pe)
#放入buffer中,参数不会训练
#因为无论是encoder还是decoder,他每一个字的维度都是d_model
#同时他们的位置编码原理是一样的
#所以一个sequence中所需要加上的positional encoding是一样的。
#所以只需要存一个pe就可以了
#同时pe是固定的参数,不需要训练
#后续代码中,如果要使用位置编码,只需要self.pe即可,因为pe已经注册在buffer里面了
def forward(self, x):
'''
x: [seq_len, batch_size, d_model]
'''
x = x + self.pe[:x.size(0), :,:]
#选取和x一样维度的seq_length,将pe加到x上
return self.dropout(x)
7.3 get-attention-pad-mask
#由于在 Encoder 和 Decoder 中都需要进行 mask 操作,
#因此就无法确定这个函数的参数中 seq_len 的值,
#如果是在 Encoder 中调用的,seq_len 就等于 src_len
#如果是在 Decoder 中调用的,seq_len 就有可能等于 src_len,
#也有可能等于 tgt_len(因为 Decoder 有两个attention模块,两次 mask)
#src_len 是在encoder-decoder中的mask
#tgt_len是decoder中的mask
def get_attn_pad_mask(seq_q, seq_k):
#对于seq_q中的每一个元素,它都会和seq_k中的每一个元素有着一个相关联系数,这个系数组成一个矩阵:
#但是因为pad的存在,pad的这些地方是不参与我们attention的计算的
#那么就是我们这里要返回的东西就是辅助得到哪些位是需要pad的
#pad的位置标记上True
'''
seq_q: [batch_size, seq_len]
seq_k: [batch_size, seq_len]
seq_len could be src_len or it could be tgt_len
seq_len in seq_q and seq_len in seq_k maybe not equal
'''
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1)
#扩展一个维度,因为attention_matrix是三维的
# pad_attn_mask [batch_size, 1, len_k]
#seq_q:[[1,2,3,4,0],[1,2,4,5,0]] ->pad_attn_mask [[F,F,F,F,T],[F,F,F,F,T]]
#通过seq_k.data.eq(0),判断哪些位是pad(pad的编码为0)
#举个例子,输入为 seq_data = [1, 2, 3, 4, 0],seq_data.data.eq(0)
#就会返回 [False, False, False, False, True]
return pad_attn_mask.expand(batch_size, len_q, len_k)
#对于每一个batch_size对应的一行,都扩充为len_q行
# [batch_size, len_q, len_k]
'''
seq_q=torch.Tensor([[1,2,3,4,0],[1,2,4,5,0]] )
print(seq_q.data.eq(0).unsqueeze(1))
print(seq_q.data.eq(0).unsqueeze(1).expand(2,5,5) )
'''
解释一下这里expand之后矩阵的意思,以及为什么每一行是一样的
1amChinesepadding我FALSEFALSEFALSETRUE是FALSEFALSEFALSETRUE中FALSEFALSEFALSETRUE国FALSEFALSEFALSETRUE人FALSEFALSEFALSETRUE
假设我们用英文翻译中文。那么我们预测每一个中文字的时候,需要每个英文单词的权重。
这个权重就是之后attention matrix每一个元素里面的东西。
所以矩阵的大小是(len_q,len_k)
而我们这个函数做的是辅助attention matrix,知道哪些位是需要padding的,哪些是不需要的。所以维度需要和attention matrix一致。
7.4 Encoder Layer(整体)
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
#多头注意力机制
self.pos_ffn = PoswiseFeedForwardNet()
#提取特征
def forward(self, enc_inputs, enc_self_attn_mask):
'''
enc_inputs: [batch_size, src_len, d_model]
enc_self_attn_mask: [batch_size, src_len, src_len]
'''
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask)
# enc_outputs: [batch_size, src_len, d_model],
#attn: [batch_size, n_heads, src_len, src_len] 每一个头一个注意力矩阵
# enc_inputs to same Q,K,V
# enc_inputs乘以WQ,WK,WV生成QKV矩阵
'''
为什么传三个?
因为这里传的是一样的
但在decoder-encoder的mulit-head里面
我们需要的decoder input ,encoder output, encoder output
所以为了使用方便,我们在定义enc_self_atten函数的时候就定义的是有三个形参的
'''
enc_outputs = self.pos_ffn(enc_outputs)
# enc_outputs: [batch_size, src_len, d_model]
#输入和输出的维度是一样的
return enc_outputs, attn
#将上述组件拼起来,就是一个完整的 Encoder Layer
7.4.1 Multihead attention
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
#三个矩阵,分别对输入进行三次线性变化
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
#变换维度
def forward(self, input_Q, input_K, input_V, attn_mask):
'''
input_Q: [batch_size, len_q, d_model]
input_K: [batch_size, len_k, d_model]
input_V: [batch_size, len_v(=len_k), d_model]
attn_mask: [batch_size, seq_len, seq_len]
'''
residual, batch_size = input_Q, input_Q.size(0)
Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1,2)
K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1,2)
V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,2)
#生成Q,K,V矩阵
'''
input_Q: [batch_size, len_q, d_model]
(W)-> [batch_size, len_q,d_k * n_heads]
(view)->[batch_size, len_q,n_heads,d_k]
(transpose)-> [batch_size,n_heads, len_q,d_k ]
'''
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
'''
attn_mask: [batch_size, seq_len, seq_len]
(unsqueeze)->[batch_size, 1, seq_len, seq_len]
(repeat)->[batch_size, n_heads, seq_len, seq_len]
'''
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
# context: [batch_size, n_heads, len_q, d_v],
#attn: [batch_size, n_heads, len_q, len_k]
context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v)
# context: [batch_size, len_q, n_heads * d_v]
output = self.fc(context)
# [batch_size, len_q, d_model]
return nn.LayerNorm(d_model).cuda()(output + residual), attn
#Add & Norm
'''
完整代码中一定会有三处地方调用 MultiHeadAttention(),Encoder Layer 调用一次,
传入的 input_Q、input_K、input_V 全部都是 enc_inputs;
Decoder Layer 中两次调用,第一次都是decoder_inputs;第二次是两个encoder_outputs和一个decoder——input
'''
7.4.2 Scaled-Dot-Product-Attention
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
'''
Q: [batch_size, n_heads, len_q, d_k]
K: [batch_size, n_heads, len_k, d_k]
V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask: [batch_size, n_heads, seq_len, seq_len]
'''
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
# scores : [batch_size, n_heads, len_q, len_k]
scores.masked_fill_(attn_mask, -1e9)
#attn_mask所有为True的部分(即有pad的部分),scores填充为负无穷,也就是这个位置的值对于softmax没有影响
attn = nn.Softmax(dim=-1)(scores)
#attn: [batch_size, n_heads, len_q, len_k]
#对每一行进行softmax
context = torch.matmul(attn, V)
# [batch_size, n_heads, len_q, d_v]
return context, attn
'''
这里要做的是,通过 Q 和 K 计算出 scores,然后将 scores 和 V 相乘,得到每个单词的 context vector
第一步是将 Q 和 K 的转置相乘没什么好说的,相乘之后得到的 scores 还不能立刻进行 softmax,
需要和 attn_mask 相加,把一些需要屏蔽的信息屏蔽掉,
attn_mask 是一个仅由 True 和 False 组成的 tensor,并且一定会保证 attn_mask 和 scores 的维度四个值相同(不然无法做对应位置相加)
mask 完了之后,就可以对 scores 进行 softmax 了。然后再与 V 相乘,得到 context
'''
7.4.3 PoswiseFeedForwardNet
用来提取特征的
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False)
)
def forward(self, inputs):
'''
inputs: [batch_size, seq_len, d_model]
'''
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(d_model).cuda()(output + residual)
# [batch_size, seq_len, d_model]
#也有残差连接和layer normalization
#这段代码非常简单,就是做两次线性变换,残差连接后再跟一个 Layer Norm
8 decoder结构
8.1 decoder 结构(整体)
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs):
'''
dec_inputs: [batch_size, tgt_len]
enc_intpus: [batch_size, src_len]
enc_outputs: [batsh_size, src_len, d_model] 经过六次encoder之后得到的东西
'''
dec_outputs = self.tgt_emb(dec_inputs)
# [batch_size, tgt_len, d_model]
#同样地,对decoder_layer进行词向量的生成
dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1).cuda()
#计算他的位置向量
# [batch_size, tgt_len, d_model]
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs).cuda()
# [batch_size, tgt_len, tgt_len]
#decoder的multi-head attention的mask(padding部分为True,其他为False)
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).cuda()
# [batch_size, tgt_len, tgt_len]
#当前时刻我是看不到未来时刻的东西的,要把之后的部门mask掉(
#看不到的部分为True,看得到的部分为False
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask), 0).cuda()
# [batch_size, tgt_len, tgt_len]
#布尔+int false 0 true 1,gt 大于 True
#这样把dec_self_attn_pad_mask和dec_self_attn_subsequence_mask里面为True的部分都剔除掉了
#也就是说,结果是所有需要被mask掉位置为True,不需要被mask掉的为False
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs)
# [batc_size, tgt_len, src_len]
#在decoder的第二个attention里面使用
dec_self_attns, dec_enc_attns = [], []
#decoder的两个attention模块
for layer in self.layers:
# dec_outputs: [batch_size, tgt_len, d_model],
#dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len],
#dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_self_attn, dec_enc_attn = \
layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
8.2 DecoderLayer
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
'''
dec_inputs: [batch_size, tgt_len, d_model]
enc_outputs: [batch_size, src_len, d_model]
dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
dec_enc_attn_mask: [batch_size, tgt_len, src_len]
'''
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
# dec_outputs: [batch_size, tgt_len, d_model],
#dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
#先是decoder的self-attention
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
# dec_outputs: [batch_size, tgt_len, d_model]
# dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
#再是encoder-decoder attention部分
dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model]
#特征提取
return dec_outputs, dec_self_attn, dec_enc_attn
#在 Decoder Layer 中会调用两次 MultiHeadAttention,第一次是计算 Decoder Input 的 self-attention,得到输出 dec_outputs。
#然后将 dec_outputs 作为生成 Q 的元素,enc_outputs 作为生成 K 和 V 的元素,再调用一次
8.2.1 get_attn_subsequence_mask
def get_attn_subsequence_mask(seq):
#Subsequence Mask 只有 Decoder的self-attention会用到,主要作用是屏蔽未来时刻单词的信息。
'''
seq: [batch_size, tgt_len]
'''
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
#[batch_size, tgt_len, tgt_len]
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # Upper triangular matrix
#首先通过 np.ones() 生成一个全 1 的方阵
#然后通过 np.triu() 生成一个上三角矩阵(对角线元素及其左下方全为0)
subsequence_mask = torch.from_numpy(subsequence_mask).byte()
#转化成byte类型的tensor
return subsequence_mask
# [batch_size, tgt_len, tgt_len]
'''
s=torch.Tensor([[1,1,1],[3,5,1]])
get_attn_subsequence_mask(s)
tensor([[[0, 1, 1],
[0, 0, 1],
[0, 0, 0]],
[[0, 1, 1],
[0, 0, 1],
[0, 0, 0]]], dtype=torch.uint8)
'''
9 定义模型,损失函数和优化函数
model = Transformer().cuda()
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.99)
10 进行训练
for epoch in range(30):
for enc_inputs, dec_inputs, dec_outputs in loader:
'''
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
dec_outputs: [batch_size, tgt_len]
'''
enc_inputs, dec_inputs, dec_outputs = enc_inputs.cuda(), dec_inputs.cuda(), dec_outputs.cuda()
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
# outputs: [batch_size * tgt_len, tgt_vocab_size]
loss = criterion(outputs, dec_outputs.view(-1))
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
'''
Epoch: 0001 loss = 2.399018
Epoch: 0002 loss = 2.190828
Epoch: 0003 loss = 2.072805
Epoch: 0004 loss = 1.816573
Epoch: 0005 loss = 1.629891
Epoch: 0006 loss = 1.342404
Epoch: 0007 loss = 1.120496
Epoch: 0008 loss = 0.945255
Epoch: 0009 loss = 0.765375
Epoch: 0010 loss = 0.597852
Epoch: 0011 loss = 0.504108
Epoch: 0012 loss = 0.368425
Epoch: 0013 loss = 0.273608
Epoch: 0014 loss = 0.239933
Epoch: 0015 loss = 0.187699
Epoch: 0016 loss = 0.161942
Epoch: 0017 loss = 0.151922
Epoch: 0018 loss = 0.103952
Epoch: 0019 loss = 0.072388
Epoch: 0020 loss = 0.080190
Epoch: 0021 loss = 0.070481
Epoch: 0022 loss = 0.054710
Epoch: 0023 loss = 0.053659
Epoch: 0024 loss = 0.047746
Epoch: 0025 loss = 0.029473
Epoch: 0026 loss = 0.039323
Epoch: 0027 loss = 0.036756
Epoch: 0028 loss = 0.014491
Epoch: 0029 loss = 0.020453
Epoch: 0030 loss = 0.024998
'''
11 测试结果
enc_inputs, dec_inputs,dec_outputs = next(iter(loader))
predict, e_attn, d1_attn, d2_attn = model(enc_inputs[0].view(1, -1).cuda(), dec_inputs[0].view(1, -1).cuda())
predict = predict.data.max(1, keepdim=True)[1]
print(enc_inputs[0], '->', [idx2word[n.item()] for n in predict.squeeze()])
#tensor([1, 2, 3, 5, 0]) -> ['i', 'want', 'a', 'coke', '.', 'E']
'''
e_attn的形状[6,8,5,5] 六层 8头 5*5
d1_attn的形状[6,8,6,6] 六层 8头 6*6(decoder自己的attention)
d2_attn的形状[6,8,6,5] 六层 8头 6*5
'''
12 可视化attention
我们以encoder 最后一层的attention为例:
x=e_attn[-1].view(8,5,5)
import seaborn
import matplotlib.pyplot as plt
for i in range(8):
plt.title('head'+str(i))
seaborn.heatmap(x[i].data.cpu(),cmap='Blues')
plt.show()




13 整体代码
#导入库
import math
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
#***********************************************#
#数据集处理
# S: Symbol that shows starting of decoding input
# E: Symbol that shows endng of decoding output
# P: Symbol that will fill in blank sequence if current batch data size is short than time steps
sentences = [
# enc_input dec_input dec_output
['ich mochte ein bier', 'S i want a beer .', 'i want a beer . E'],
['ich mochte ein cola', 'S i want a coke .', 'i want a coke . E']
]
#encoder input和decoder input就不用说了,分别是transformer中encoder和decoder的输入
#decoder output就是我们理论上需要输出的东西(ground truth)(预测的句子和这个进行比对,算loss)
#这里的输入数据集只是两对英德句子,每个字的索引(vocab)也是手动编码上去的
src_vocab = {'P' : 0, 'ich' : 1, 'mochte' : 2, 'ein' : 3, 'bier' : 4, 'cola' : 5}
# Padding Should be Zero
#每一个batch里面的句子长度是一样的,那么不足的部分就需要补Padding
src_vocab_size = len(src_vocab)
tgt_vocab = {'P' : 0, 'i' : 1, 'want' : 2, 'a' : 3, 'beer' : 4, 'coke' : 5, 'S' : 6, 'E' : 7, '.' : 8}
idx2word = {i: w for i, w in enumerate(tgt_vocab)}
tgt_vocab_size = len(tgt_vocab)
#***********************************************#
#参数定义4
src_len = 5 # enc_input max sequence length
#encoder 输入的句子的长度(不足的部分补padding)
tgt_len = 6 # dec_input(=dec_output) max sequence length
#decoder输出的目标句子的长度(算上起始符S和终止符E之后)
#***********************************************#
#transformer的参数
# Transformer Parameters
d_model = 512
#每一个词的 word embedding 用多少位表示
#(包括positional encoding应该用多少位表示,因为这两个要维度相加,应该是一样的维度)
d_ff = 2048 # FeedForward dimension
#forward线性层变成多少位(d_model->d_ff->d_model)
d_k = d_v = 64 # dimension of K(=Q), V
#K,Q,V矩阵的维度(K和Q一定是一样的,因为要K乘Q的转置),V不一定
'''
换一种说法,就是我在进行self-attention的时候,
从input(当然是加了位置编码之后的input)线性变换之后的三个向量 K,Q,V的维度
'''
n_layers = 6
#encoder和decoder各有多少层
n_heads = 8
#multi-head attention有几个头
#***********************************************#
#数据预处理
# 将encoder_input、decoder_input和decoder_output进行id化
def make_data(sentences):
enc_inputs, dec_inputs, dec_outputs = [], [], []
for i in range(len(sentences)):
#对于输入的每一句话
enc_input = [src_vocab[n] for n in sentences[i][0].split()]
# 每一次生成这一行sentence中encoder_input对应的id编码
for _ in range(src_len-len(enc_input)):
enc_input.append(0)
dec_input = [tgt_vocab[n] for n in sentences[i][1].split()]
# 每一次生成这一行sentence中decoder_input对应的id编码
for _ in range(tgt_len-len(dec_input)):
dec_input.append(0)
dec_output = [tgt_vocab[n] for n in sentences[i][2].split()]
# 每一次生成这一行sentence中decoder_output对应的id编码
for _ in range(tgt_len-len(dec_output)):
dec_output.append(0)
#分别对encoder-input、decoder-input、decoder-output进行处理,分别放到一个list里面
enc_inputs.append(enc_input)
dec_inputs.append(dec_input)
dec_outputs.append(dec_output)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
#***********************************************#
class MyDataSet(Data.Dataset):
def __init__(self, enc_inputs, dec_inputs, dec_outputs):
super(MyDataSet, self).__init__()
self.enc_inputs = enc_inputs
self.dec_inputs = dec_inputs
self.dec_outputs = dec_outputs
def __len__(self):
return self.enc_inputs.shape[0]
#有几个sentence
def __getitem__(self, idx):
return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
#根据索引找encoder_input,decoder_input,decoder_output
loader = Data.DataLoader(
MyDataSet(enc_inputs, dec_inputs, dec_outputs),
batch_size=2,
shuffle=True)
#***********************************************#
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
#max_length_(一个sequence的最大长度)
pe = torch.zeros(max_len, d_model)
#pe [max_len,d_model]
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
#position [max_len,1]
div_term = torch.exp(
torch.arange(0, d_model, 2).float()
* (-math.log(10000.0) / d_model))
#div_term:[d_model/2]
#e^(-i*log10000/d_model)=10000^(-i/d_model)
#d_model为embedding_dimension
#两个相乘的维度为[max_len,d_model/2]
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
#计算position encoding
#pe的维度为[max_len,d_model],每一行的奇数偶数分别取sin和cos(position * div_term)里面的值
pe = pe.unsqueeze(0).transpose(0, 1)
#维度变成(max_len,1,d_model)
#所以直接用pe=pe.unsqueeze(1)也可以
self.register_buffer('pe', pe)
#放入buffer中,参数不会训练
def forward(self, x):
'''
x: [seq_len, batch_size, d_model]
'''
x = x + self.pe[:x.size(0), :,:]
#选取和x一样维度的seq_length,将pe加到x上
return self.dropout(x)
#***********************************************#
#由于在 Encoder 和 Decoder 中都需要进行 mask 操作,
#因此就无法确定这个函数的参数中 seq_len 的值,
#如果是在 Encoder 中调用的,seq_len 就等于 src_len
#如果是在 Decoder 中调用的,seq_len 就有可能等于 src_len,
#也有可能等于 tgt_len(因为 Decoder 有两次 mask)
#src_len 是在encoder-decoder中的mask
#tgt_len是decdoer mask
def get_attn_pad_mask(seq_q, seq_k):
#对于seq_q中的每一个元素,它都会和seq_k中的每一个元素有着一个相关联系数,这个系数组成一个矩阵:
#但是因为pad的存在,pad的这些地方是不参与我们attention的计算的,那么就是我们这里要返回的东西就是辅助得到哪些位是pad
'''
seq_q: [batch_size, seq_len]
seq_k: [batch_size, seq_len]
seq_len could be src_len or it could be tgt_len
seq_len in seq_q and seq_len in seq_k maybe not equal
'''
#pad的位置标记上True
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
#seq_q:[[1,2,3,4,0],[1,2,4,5,0]] ->pad_attn_mask [[F,F,F,F,T],[F,F,F,F,T]]
#扩展一个维度,因为word embedding是三维的
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1)
# pad_attn_mask [batch_size, 1, len_k], False is masked
#通过seq_k.data.eq(0),判断哪些位是pad(pad的编码为0)
#举个例子,输入为 seq_data = [1, 2, 3, 4, 0],seq_data.data.eq(0) 就会返回 [False, False, False, False, True]
return pad_attn_mask.expand(batch_size, len_q, len_k)
#对于每一个batch_size对应的一行,都扩充为len_q行
# [batch_size, len_q, len_k]
#***********************************************#
def get_attn_subsequence_mask(seq):
#Subsequence Mask 只有 Decoder的self-attention会用到,主要作用是屏蔽未来时刻单词的信息。
'''
seq: [batch_size, tgt_len]
'''
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
#[batch_size, tgt_len, tgt_len]
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # Upper triangular matrix
#首先通过 np.ones() 生成一个全 1 的方阵,然后通过 np.triu() 生成一个上三角矩阵(对角线元素及其左下方全为0)
subsequence_mask = torch.from_numpy(subsequence_mask).byte()
#转化成byte类型的tensor
return subsequence_mask # [batch_size, tgt_len, tgt_len]
#***********************************************#
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
'''
Q: [batch_size, n_heads, len_q, d_k]
K: [batch_size, n_heads, len_k, d_k]
V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask: [batch_size, n_heads, seq_len, seq_len]
'''
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
# scores : [batch_size, n_heads, len_q, len_k]
scores.masked_fill_(attn_mask, -1e9)
#attn_mask所有为True的部分(即有pad的部分),scores填充为负无穷,也就是这个位置的值对于softmax没有影响
attn = nn.Softmax(dim=-1)(scores)
#attn: [batch_size, n_heads, len_q, len_k]
#对每一行进行softmax
context = torch.matmul(attn, V)
# [batch_size, n_heads, len_q, d_v]
return context, attn
'''
这里要做的是,通过 Q 和 K 计算出 scores,然后将 scores 和 V 相乘,得到每个单词的 context vector
第一步是将 Q 和 K 的转置相乘没什么好说的,相乘之后得到的 scores 还不能立刻进行 softmax,
需要和 attn_mask 相加,把一些需要屏蔽的信息屏蔽掉,
attn_mask 是一个仅由 True 和 False 组成的 tensor,并且一定会保证 attn_mask 和 scores 的维度四个值相同(不然无法做对应位置相加)
mask 完了之后,就可以对 scores 进行 softmax 了。然后再与 V 相乘,得到 context
'''
#***********************************************#
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
#三个矩阵,分别对输入进行三次线性变化
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
#变换维度
def forward(self, input_Q, input_K, input_V, attn_mask):
'''
input_Q: [batch_size, len_q, d_model]
input_K: [batch_size, len_k, d_model]
input_V: [batch_size, len_v(=len_k), d_model]
attn_mask: [batch_size, seq_len, seq_len]
'''
residual, batch_size = input_Q, input_Q.size(0)
# [batch_size, len_q, d_model]
#(W)-> [batch_size, len_q,d_k * n_heads]
#(view)->[batch_size, len_q,n_heads,d_k]
#(transpose)-> [batch_size,n_heads, len_q,d_k ]
Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1,2)
K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1,2)
V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,2)
#生成Q,K,V矩阵
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
# attn_mask : [batch_size, n_heads, seq_len, seq_len]
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
# context: [batch_size, n_heads, len_q, d_v],
#attn: [batch_size, n_heads, len_q, len_k]
context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v)
# context: [batch_size, len_q, n_heads * d_v]
output = self.fc(context)
# [batch_size, len_q, d_model]
return nn.LayerNorm(d_model).cuda()(output + residual), attn
'''
完整代码中一定会有三处地方调用 MultiHeadAttention(),Encoder Layer 调用一次,
传入的 input_Q、input_K、input_V 全部都是 enc_inputs;
Decoder Layer 中两次调用,第一次都是decoder_inputs;第二次是两个encoder_outputs和一个decoder——input
'''
#***********************************************#
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False)
)
def forward(self, inputs):
'''
inputs: [batch_size, seq_len, d_model]
'''
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(d_model).cuda()(output + residual) # [batch_size, seq_len, d_model]
#也有残差连接和layer normalization
#这段代码非常简单,就是做两次线性变换,残差连接后再跟一个 Layer Norm
#***********************************************#
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
#多头注意力机制
self.pos_ffn = PoswiseFeedForwardNet()
#提取特征
def forward(self, enc_inputs, enc_self_attn_mask):
'''
enc_inputs: [batch_size, src_len, d_model]
enc_self_attn_mask: [batch_size, src_len, src_len]
'''
# enc_outputs: [batch_size, src_len, d_model],
#attn: [batch_size, n_heads, src_len, src_len] 每一个投一个注意力矩阵
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask)
# enc_inputs to same Q,K,V
#乘以WQ,WK,WV生成QKV矩阵(为什么传三个?因为这里传的是一样的
#但在decoder-encoder的mulit-head里面,我们需要的decoder input encoder output encoder output
#所以为了使用方便,我们在定义enc_self_atten函数的时候就定义的使有三个形参的
enc_outputs = self.pos_ffn(enc_outputs)
# enc_outputs: [batch_size, src_len, d_model]
#输入和输出的维度是一样的
return enc_outputs, attn
#将上述组件拼起来,就是一个完整的 Encoder Layer
#***********************************************#
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
'''
dec_inputs: [batch_size, tgt_len, d_model]
enc_outputs: [batch_size, src_len, d_model]
dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
dec_enc_attn_mask: [batch_size, tgt_len, src_len]
'''
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
# dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
#先是decoder的self-attention
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
#再是encoder-decoder attention部分
dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model]
#特征提取
return dec_outputs, dec_self_attn, dec_enc_attn
#在 Decoder Layer 中会调用两次 MultiHeadAttention,第一次是计算 Decoder Input 的 self-attention,得到输出 dec_outputs。
#然后将 dec_outputs 作为生成 Q 的元素,enc_outputs 作为生成 K 和 V 的元素,再调用一次 MultiHeadAttention,得到的是 Encoder 和 Decoder Layer 之间的 context vector。最后将 dec_outptus 做一次维度变换,然后返回
#***********************************************#
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model)
#对encoder的输入的每个单词进行词向量计算词向量/字向量(src——vocab_size个词,每个词d_model的维度)
self.pos_emb = PositionalEncoding(d_model)
#计算位置向量
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
#将6个EncoderLayer组成一个module
def forward(self, enc_inputs):
'''
enc_inputs: [batch_size, src_len]
'''
enc_outputs = self.src_emb(enc_inputs)
#对每个单词进行词向量计算
#enc_outputs [batch_size, src_len, d_model]
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1)
#添加位置编码
# enc_outputs [batch_size, src_len, d_model]
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs)
# enc_self_attn: [batch_size, src_len, src_len]
#计算得到encoder-attention的pad martix
enc_self_attns = []
#创建一个列表,保存接下来要返回的字-字attention的值,不参与任何计算,供可视化用
for layer in self.layers:
# enc_outputs: [batch_size, src_len, d_model]
# enc_self_attn: [batch_size, n_heads, src_len, src_len]
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
#再传进来就不用positional decoding
#记录下每一次的attention
return enc_outputs, enc_self_attns
#使用 nn.ModuleList() 里面的参数是列表,列表里面存了 n_layers 个 Encoder Layer
#由于我们控制好了 Encoder Layer 的输入和输出维度相同,所以可以直接用个 for 循环以嵌套的方式,
#将上一次 Encoder Layer 的输出作为下一次 Encoder Layer 的输入
#***********************************************#
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs):
'''
dec_inputs: [batch_size, tgt_len]
enc_intpus: [batch_size, src_len]
enc_outputs: [batsh_size, src_len, d_model] 经过六次encoder之后得到的东西
'''
dec_outputs = self.tgt_emb(dec_inputs)
# [batch_size, tgt_len, d_model]
#同样地,对decoder_layer进行词向量的生成
dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1).cuda()
#计算他的位置向量
# [batch_size, tgt_len, d_model]
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs).cuda()
# [batch_size, tgt_len, tgt_len]
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).cuda()
# [batch_size, tgt_len, tgt_len]
#当前时刻我是看不到未来时刻的东西的
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask), 0).cuda()
# [batch_size, tgt_len, tgt_len]
#布尔+int false 0 true 1,gt 大于 True
#这样把dec_self_attn_pad_mask和dec_self_attn_subsequence_mask里面为True的部分都剔除掉了
#也就是说,即屏蔽掉了pad也屏蔽掉了mask
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # [batc_size, tgt_len, src_len]
#在decoder的第二个attention里面使用
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
# dec_outputs: [batch_size, tgt_len, d_model],
#dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len],
#dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_self_attn, dec_enc_attn = \
layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
#***********************************************#
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder().cuda()
self.decoder = Decoder().cuda()
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False).cuda()
#对decoder的输出转换维度,
#从隐藏层维数->英语单词词典大小(选取概率最大的那一个,作为我们的预测结果)
def forward(self, enc_inputs, dec_inputs):
'''
enc_inputs维度:[batch_size, src_len]
对encoder-input,我一个batch中有几个sequence,一个sequence有几个字
dec_inputs: [batch_size, tgt_len]
对decoder-input,我一个batch中有几个sequence,一个sequence有几个字
'''
# enc_outputs: [batch_size, src_len, d_model],
# d_model是每一个字的word embedding长度
"""
enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]
注意力矩阵,对encoder和decoder,每一层,每一句话,每一个头,每两个字之间都有一个权重系数,
这些权重系数组成了注意力矩阵(之后的dec_self_attns同理,当然decoder还有一个decoder-encoder的矩阵)
"""
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
# dec_outpus: [batch_size, tgt_len, d_model],
#dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len],
#dec_enc_attn: [n_layers, batch_size, tgt_len, src_len]
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
dec_logits = self.projection(dec_outputs)
#将输出的维度,从 [batch_size, tgt_len, d_model]变成[batch_size, tgt_len, tgt_vocab_size]
# dec_logits: [batch_size, tgt_len, tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
#dec_logits 的维度是 [batch_size * tgt_len, tgt_vocab_size],可以理解为,
#一个句子,这个句子有 batch_size*tgt_len 个单词,每个单词有 tgt_vocab_size 种情况,取概率最大者
#Transformer 主要就是调用 Encoder 和 Decoder。最后返回
#***********************************************#
model = Transformer().cuda()
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.99)
#***********************************************#
for epoch in range(30):
for enc_inputs, dec_inputs, dec_outputs in loader:
'''
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
dec_outputs: [batch_size, tgt_len]
'''
enc_inputs, dec_inputs, dec_outputs = enc_inputs.cuda(), dec_inputs.cuda(), dec_outputs.cuda()
# outputs: [batch_size * tgt_len, tgt_vocab_size]
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
loss = criterion(outputs, dec_outputs.view(-1))
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
enc_inputs, dec_inputs,dec_outputs = next(iter(loader))
predict, e_attn, d1_attn, d2_attn = model(enc_inputs[0].view(1, -1).cuda(), dec_inputs[0].view(1, -1).cuda())
predict = predict.data.max(1, keepdim=True)[1]
print(enc_inputs[0], '->', [idx2word[n.item()] for n in predict.squeeze()])
|